
Squelching bad vibe coding
If you're gonna spew code, spew it into this set of controls
I first began to believe that LLMs were capable of generating more than just little snippets of code in fall 2023. I started by experimenting with what’s now called vibe coding, just to see what an LLM could do on its own. I dropped it once I got past trivial problems—it was clear that the LLM needed precise guidance for anything complex or nuanced.
That led me to trying test-driven development (TDD) with the LLM: Write a little test, get it to pass, clean it up, repeat. The idea was that having a test for each distinct behavior would guide the LLM in arbitrating a solution. But interacting with the LLM throughout the TDD cycle was too granular to be effective—particularly without any sort of built-in IDE support.

After discarding my purist TDD interests, I decided to brainstorm a better approach to AI-assisted development, one that also heavily involved using tests to verify the generated code.
I’d gathered a few observations during my casual experimentation:
I could get an LLM to produce correct solutions occasionally, given only a brief description of the problem.
When the LLM generated defective code, I was in all cases able to negotiate with the LLM to arrive at a correct solution. Sometimes this negotiation took over a half-dozen attempts, however, and sometimes it involved reconsidering the design.
I was able to have the LLM generate unit tests (as well as other kinds of tests), by prompting it with examples that described all the desired scenarios. Each example succinctly captured the expected output for a given set of inputs (or series of operations). The generated tests had high fidelity with the examples.
The LLM generated low quality code by default—procedural, unnecessarily complex, and with minimal abstraction1.
When providing the LLM with a set of design guidelines (such as “extract all small conceptual chunks to separate functions”), it produced higher-quality code, usually sufficient for my interests.
The LLM ignored some of the design guidelines from time to time.
The following insights came out of my brainstorming2:
Rather than generating code at the function level, focus on generating a complete, single-responsibility, closed class (or module). If I want to change the behaviors of a generated class, I regenerate it entirely.
Generate tests at the same time as the code, using a set of examples that comprehensively describes the module/class. Quickly vet these tests for fidelity with the examples.
Provide a very small set of design guidelines (predominantly around promoting functional solutions with high abstraction) with each prompt.
Two big hypotheses also followed these initial insights:
Providing the LLM with examples improves compliance.
Providing the LLM with code/design guidelines improves compliance (in addition to improving the ability to negotiate when it generates a non-compliant solution).
I’m working to create tooling to help prove or disprove these and similar hypotheses.
Somewhere before mid-2024, I started building a process around this notion of AI-Assisted Development with Verification—AADV3. Its centerpiece is a technique I named CAX—Create, Assess, eXecute—in which you use the LLM to generate both tests and code, assess the tests, then run them. You repeat the cycle until all tests pass when executed.
The AADV process, still under development, consists of a prime directive, CAX, an in-flux set of design prompts, guidelines for creating examples (based off well-known testing principles), and an evolving design philosophy on creating “pluggable” systems.
Think of it as “vibe coding with proper safeguards.” It’s not likely that you’ll succeed without some grounding in—or interest in learning enough about—good old-fashioned systems design and testing principles.
Vibe coding without proper safeguards is a mistake for most of us.
Design Lives!
Delivering a sustainable system with AADV will continue to require your design skills. If the idea is to assemble a bunch of LLM-generated components to create that system, you must still understand how big a module should be (what set of responsibilities it should contain), what its public interface must look like, how to orchestrate logic to accomplish desired behaviors, and so on.
In short, think of it this way: Under AADV, you use the CAX cycle to “only” generate code for your tests and functions/methods. You’re still responsible for designing everything outside the implementation specifics.
A shift in mindset
The more I generate code with my LLM, the less I care what the implementation of my functions look like. Here’s old-school generated code to determine if a word is an isogram and thus does not contain repeated letters:
export function isIsogram(str) {
var seen = []
var lower = ''
for (var i = 0; i < str.length; i++) {
var c = str[i].toLowerCase()
if (c === ' ' || c === '-') continue
lower += c
}
for (var j = 0; j < lower.length; j++) {
if (seen.indexOf(lower[j]) !== -1) {
return false
}
seen.push(lower[j])
}
return true
}(Maybe we could agree to just have LLMs build everything in C.)
Here’s generated code I’d be happier (not happiest) with:
export const isIsogram = str => {
const lettersOnlyToLower = str.toLowerCase().replace(/[^a-z]/g, '')
return new Set(lettersOnlyToLower).size === lettersOnlyToLower.length
}(You can find the CAX examples in the footnotes4.)
But nowadays I don’t care much which generated implementation I land on, as long as it works. I don’t have to maintain the code within isIsogram. I do still need to concern myself with everything else in software development, such as modular design and performance. I also know I can trust isIsogram to do its job because I was following CAX.
Having said all that, the implementation specifics do matter if it’s not right. When a sloppy solution isn’t compliant, I ask for a more-scannable (modern) implementation—something I can glance at and understand.
As someone who had found decades of joy in crafting what I believe to be elegant, highly-maintainable code, I’m surprised at what I’m promoting. With AADV, I’m indifferent to the inner workings of all the functions, and that’s OK. Nowadays I usually only quickly scan the innards of a module, mostly looking for anything that looks out of place. I don’t have the time to read all the implementation details5, and I don’t need to.
A worsening diet
Humans have created at least a trillion lines of code since the 1950s. AI is likely to more than equal that output within five years6.
That’s a dramatic statement. You want more dramatic? Sure:
At least 80%7 of our first trillion lines of code are in low-quality codebases.
The vast amount of inelegant code isn’t at all surprising. We saw growing swells of interest from the 1980s through the 2000s for high quality design. The 80s brought us heavily structured design. The 90s brought us “big design up front” and design patterns. The 00s saw a massive shift from speculative design to continuous (iterative/incremental) design, supported by techniques including TDD and refactoring.
By 2015, serious discourse around software design had largely faded. Advocates of either side of the pro-design spectrum—big design up front or disciplined evolutionary design—were becoming a minority. In 2025, the dominant approach is simple: spew it and ship it.
Today’s LLMs gorged themselves on massive piles of low-quality code: redundant, poorly structured, and lacking tests. As a result, the trillion-plus lines of AI-generated code to quickly come will exist in an equally large percentage of low-quality codebases. Are we doomed to the ouroboros effect of LLMs eating their own tail, endlessly feeding on their own spewage?
Bad Vibes
There's a new kind of coding I call vibe coding, where you fully give in to the vibes,
embrace exponentials, and forget that the code even exists.
It's possible because the LLMs are getting too good. — Andrej Karpathy, X.com
Make sure you read the title of this AI Code Correct post as “vibe coding that happens to have a bad outcome,” not as “vibe coding is bad.”
Still, you know how things are: The label—or the vibe of the label—is often what sticks. Too many developers will do exactly what Karpathy is suggesting: Generate code with an LLM, look it over for defects, perhaps run a few manual tests, and ship it.
Unfortunately, too many of those developers won’t find enough defects in that process. “Vibe coding” will lead to an unnecessary backlash against AI coding8.
There’s a simple fact to admit: AI can only guess at all the little nuances that matter. Human-provided clarifying examples are and will be our best way to express those nuances for some time. (At some point, though, you will likely be able to live-vibe-code, seeing the application change in front of your eyes as an AI partner asks you enough questions to iron out the ambiguities.)
The code integrity matrix
If you cross-section code quality with effective test coverage, you get what I’ve termed the code integrity matrix.
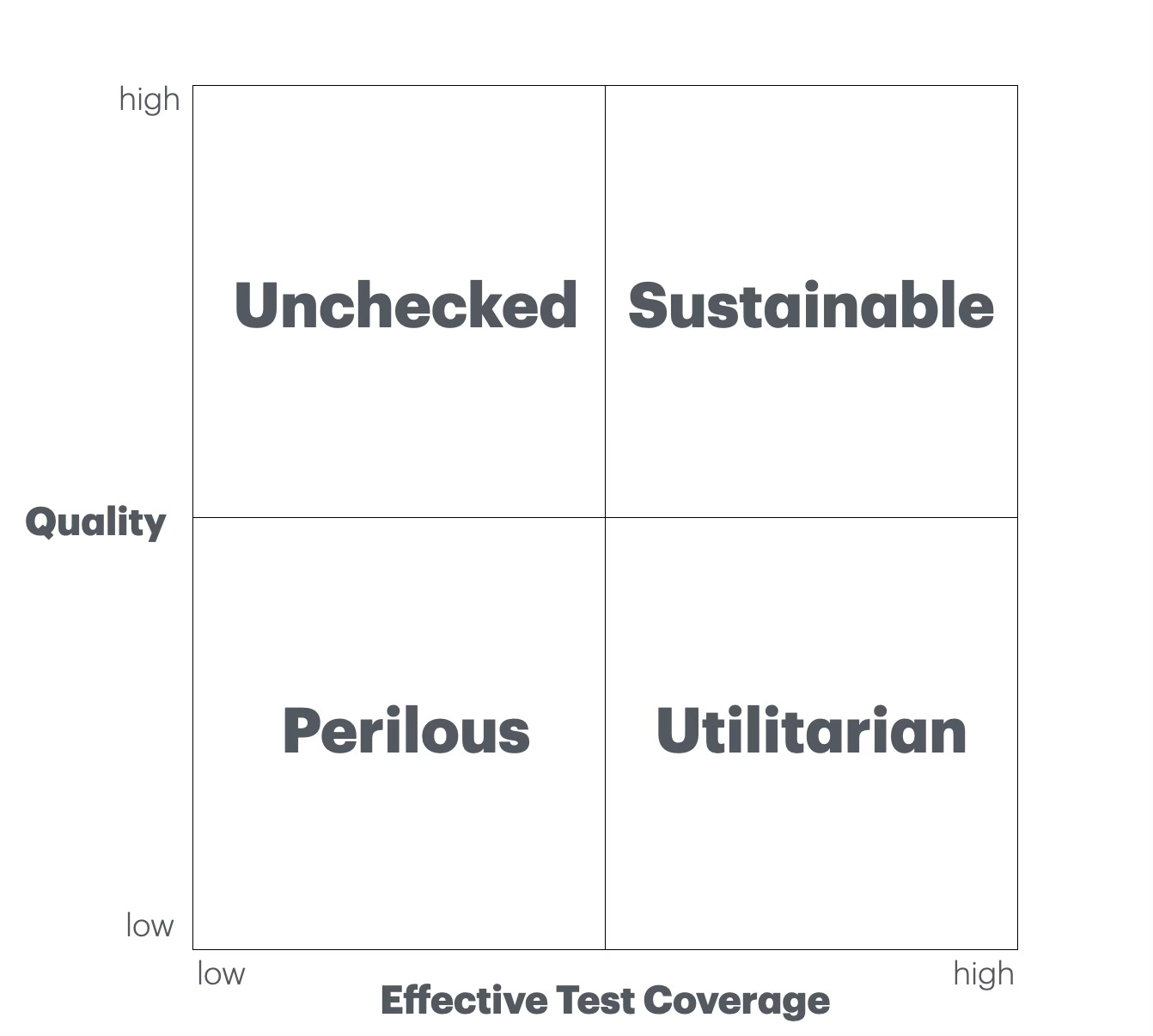
Perilous code: We shouldn’t ever ship low-quality, poorly-tested code. But we do. We might have been able to slap it out, but it will cost us increasingly dearly over time.
Unchecked code: We’ve invested time painstakingly crafting well-designed code without tests. While the better design allows us to more easily adapt the software, we’ll do so at a slow pace.
Sustainable code: We’ve invested time to painstakingly craft properly-designed code and corresponding quality controls. Costs will remain reasonable as we continue to change the software.
Utilitarian code: We’ve invested time creating proper quality controls, but haven’t taken advantage of them to keep the code clean. Humans can safely change the code, but costs will be higher than for sustainable code. This is the sweet spot for CAX, which allows rapid generation of both adequate-quality production code and high-fidelity automated tests.
Maximal effective coverage exists when the tests verify all the behaviors intended by its developers. (It’s possible that your code coverage tool shows high coverage even when some features aren’t at all verified.)
Ultimately, your choice of code integrity quadrants is up to you. If you’ve determined that your customers / users are willing to accept perilous solutions, that’s your prerogative. Vibe coding alone will get you there.
Consider AADV + CAX as “vibe coding plus,” a simple and streamlined way to emanate positive vibes while letting your LLM create the implementation details. You’ll quickly produce trustworthy solutions that lie in the high part of the utilitarian quadrant.
Low quality here indicates code that’s hard to maintain. Code that doesn’t do what it’s asked is defective or noncompliant.
It took maybe 15-20 minutes—these aren’t startling or complex insights, so I was surprised that no one else had arrived at this approach.
Indeed mundane but concise.
CAX examples for isIsogram:
input is an isogram when
is word with unique letters
smelt
is hyphenated word with unique letters
go-kart
is sentence with unique letters
flux zebra hit
input is not an isogram when
is word with duplicated letters
puzzlement
is hyphenated word with duplicated letters
know-it-all
is sentence with duplicated letters
subterranean homesick alienTo quote Rat from Fast Times at Ridgemont High, “It would take too long to look through all that stuff.”)
Both these quantities were guesstimated by ChatGPT.
Also ChatGPT.
I think bad vibe coding will usher the end for many human coders soon after the likely backlash. Folks paying for software will at first accept the notion that LLMs are to blame, but will soon realize that they’d been misled.